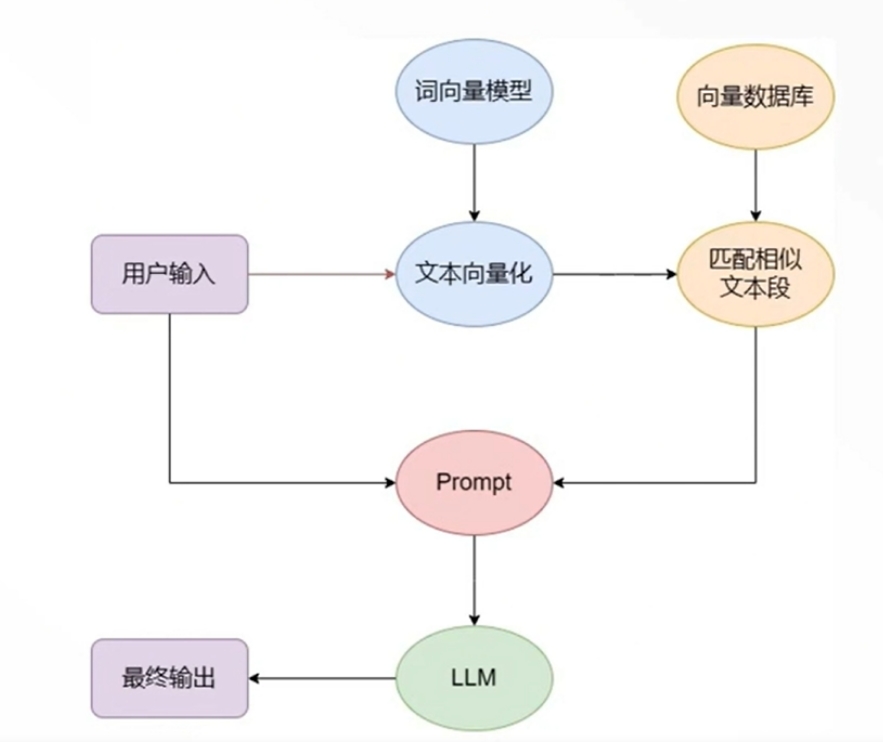
rag
ollama
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
ollama run deepseek-r1:1.5b
windows %APPDATA%\Microsoft\Windows\Start Menu\Programs\Startup
OLLAMA_MODELS
OLLAMA_HOST
OLLAMA_ORIGINS *
OLLAMA_KEEP_ALIVE 0
langchain 数据感知:将语言模型连接到其他数据源 自主性:允许语言模型与其环境进行交互
rag Retrieval Augmented Generation 增强式信息检索生成
HuggingFace 开源社区和平台,专注于自然语言处理(NLP)技术的研究和开发
模型(models) : LangChain 支持的各种模型类型和模型集成。
提示(prompts) : 包括提示管理、提示优化和提示序列化。
内存(memory)也叫记忆存储 : 内存是在链/代理调用之间保持状态的概念。LangChain提供了一个标准的内存接口、一组内存实现及使用内存的链/代理示例。
索引(indexes) : 与您自己的文本数据结合使用时,语言模型往往更加强大——此模块涵盖了执行此操作的最佳实践。
链(chains) : 链不仅仅是单个 LLM 调用,还包括一系列调用(无论是调用 LLM 还是不同的实用工具)。LangChain
提供了一种标准的链接口、许多与其他工具的集成。LangChain 提供了用于常见应用程序的端到端的链调用。
代理(agents) : 代理涉及 LLM 做出行动决策、执行该行动、查看一个观察结果,并重复该过程直到完成。LangChain
提供了一个标准的代理接口,一系列可供选择的代理,以及端到端代理的示例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
向量数据库
Qdrant: Qdrant 使用三种类型的索引来支持其数据库。这三个索引是Payload索引,类似于传统的面向文档的数据库中的索引;字符串有效负载的全文索引;和向量索引。他们的混合搜索方法是向量搜索与属性过滤的组合。
Pinecone: RBAC 对于大型组织来说还不够。存储优化 (S1) 存在一些性能挑战,只能获得 10-50 QPS。命名空间的数量是有限的,用户在使用元数据过滤作为解决此限制的方法时应小心,因为它会对性能产生很大影响。此外,这种方法无法实现数据隔离。
Weaviate: Weaviate 使用两种类型的索引来支持其数据库。倒排索引将数据对象属性映射到其在数据库中的位置,向量索引支持高性能查询。此外,其混合搜索方法使用密集向量来理解查询的上下文,并将其与稀疏向量相结合以进行关键字匹配。
Chroma:Chroma 使用 HNSW 算法支持 kNN 搜索。
Milvus: Milvus 支持多个内存索引和表级分区,从而满足实时信息检索系统所需的高性能。 RBAC 支持是企业级应用程序的要求。关于分区,通过将搜索限制为数据库的一个或多个子集,与静态分片相比,分区可以提供一种更有效的数据过滤方式,静态分片可能会引入瓶颈,并且当数据增长超出服务器容量时需要重新分片。分区是一种管理数据的好方法,它可以根据类别或时间范围将数据分组为子集。这可以帮助您轻松过滤和搜索大量数据,而不必每次都搜索整个数据库。没有一种索引类型可以适合所有用例,因为每个用例都会有不同的权衡。通过支持更多索引类型,您可以更灵活地在准确性、性能和成本之间找到平衡。
Faiss: FAISS是一种支持kNN搜索的算法
1
2
3
4
5
6
7
8
9
10
11
LEDVR 工作流
数据增强模块是一个多功能的数据增强集成工具,一般称作 LEDVR 其中:
L代表加载器(Loader)
E代表嵌入模型包装器(Text EmbeddingModcl)
D代表文档转换器( Document Transformers)
V代表向量存储库( VectorStore )
R代表检索器(Retriever)
1
2
3
4
5
6
7
8
大模型的预训练、微调和蒸馏
预训练 大学通识教育 通用能力
微调 专业培训 特定任务
蒸馏 经验传承 老带新
预训练使用海量无标注标注数据(如互联网文本、图像库)进行通识教育(大学基础课程);
微调使用专业领域标注数据(如医疗影像、法律文书、代码库)进行专业培训(入职后的岗位技能培训);
蒸馏使用教师模型的输出(如概率分布、推理链)进行经验传承(老员工带新人)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
openclaw vs claude code
工具 核心优势 适用场景 局限性
OpenClaw 任务拆解、信息检索、文档生成、流程协调 项目规划、需求分析、文档撰写、进度管理 无代码执行能力,需手动对接开发工具
Claude Code 代码编写、调试重构、测试执行、语法纠错 功能开发、bug修复、代码优化 无宏观任务规划能力,依赖人工下达指令
1
2
3
4
mcp skills agents
llm 大语言模型
MCP ──→ 给AI装上"手"和"脚",能干活
Rules ──→ 制定"项目宪法",让AI知道怎么做
Skills ──→ 召唤"领域专家",专门回答特定问题
Agents ──→ 分配"专人负责",处理特定任务
Hooks ──→ 设置"自动触发",保存提交时执行
大模型 + RAG + MCP工具 + Agent引擎 + Skill生态 = 真正能干活的AI
Agent = LLM (大脑) + Planning (规划) + Tool use (执行) + Memory (记忆)。
ReAct = Reasoning(推理)+ Acting(行动)
1
2
3
4
5
6
7
8
9
10
11
12
13
langchain
LangChain 模块总览:
LLMs / ChatModels:模型接口
Prompt Templates:Prompt 结构化
Chains:流程编排 (LCEL) LangChain Expression Language
Memory:上下文管理
Retrievers / VectorStores:知识检索
Agents & Tools:自动决策与执行
1
2
3
4
5
6
7
8
9
SDD OpenSpec
SDD(Spec-Driven Development)和OpenSpec介绍
规范驱动开发(Spec-Driven Development),简单说就是先定规矩,再写代码
npm install -g @fission-ai/openspec@latest
1
2
3
4
5
